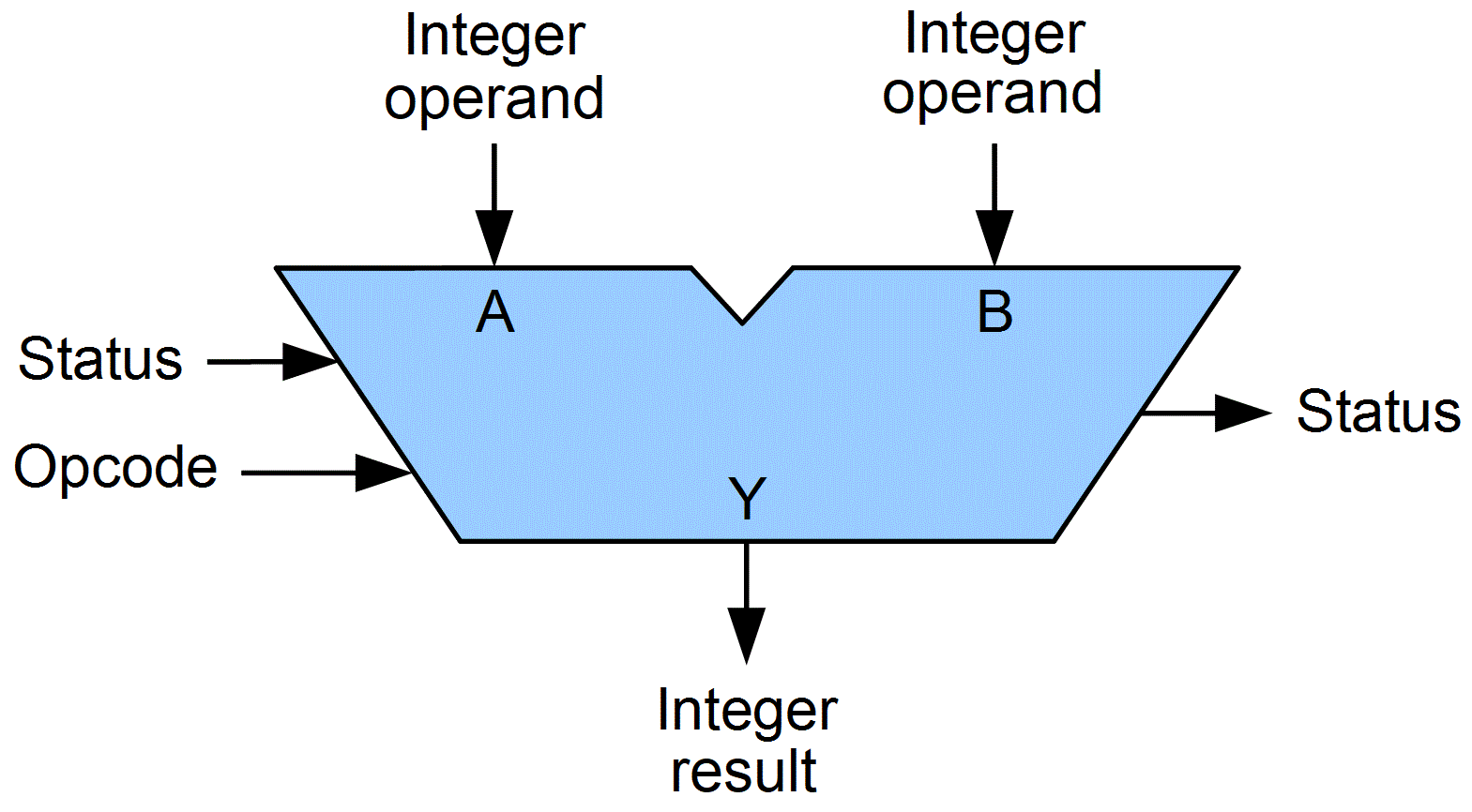
Profiling can be used to determine the performance of a system
Simple ALU, what takes time is loops
Types of loop optimization
Multicolumn
Blank
1. Loop Jamming (Loop Fusion)
Combines two or more separate loops that iterate over the same range into a single loop.
Before
for (int i=0; i < 1000; i++) { a[i] = 5;}for (int i=0; i < 1000; i++) { b[i] = 10;}
After
for (int i=0; i < 1000; i++) { a[i] = 5; b[i] = 10;}
Pro: Reduces loop overhead. The setup, increment, and conditional check (i++, i < 1000) are only performed once instead of twice.
Con: Only possible if the loops have the exact same iteration range and the second loop doesn’t depend on the completed results of the first.
2. Loop Hoisting
Moves “loop-invariant” code—calculations that produce the same result in every single iteration—out of the loop and places it just before the loop begins.
Before
for (int i=0; i < 1000; i++) { // This calculation is the same every time array[i] = x + y;}
After
// Hoist the invariant calculationint temp = x + y;for (int i=0; i < 1000; i++) { array[i] = temp;}
Pro: Prevents redundant work. The x + y operation is performed only once instead of 1,000 times.
Con: Many modern compilers are already very good at performing this optimization automatically.
3. Loop Un-switching
Moves an if statement inside a loop to outside the loop, duplicating the loop within each branch. This is only done when the if condition is loop-invariant.
Before
for (int i=0; i < 1000; i++) { // 'e' does not change inside the loop if (e > 0) { array[i] = e; } else { array[i] = c; }}
After
// Check the invariant condition only onceif (e > 0) { for (int i=0; i < 1000; i++) { array[i] = e; }} else { for (int i=0; i < 1000; i++) { array[i] = c; }}
Pro: Eliminates a conditional branch check from every single iteration of the loop.
Con: Increases the final code size because the loop’s body is duplicated.
Blank
4. Loop Peeling
Separates one or more “problematic” iterations from the beginning (prologue) or end (epilogue) of the loop, allowing the main loop kernel to be simpler.
Before
// The first iteration (i=0) uses p=18,// but all others use the previous 'i'.long int p = 18;for (long int i=0; i < 1000; ++i) { y_array[i] = array[i] + array[p]; p = i;}
After
// "Peeled" first iteration (i=0)y_array[0] = array[0] + array[18];// The main loop kernel is now simplerfor (long int i=1; i < 1000; ++i) { // 'p' is just the previous 'i', so (i-1) y_array[i] = array[i] + array[i-1];}
Pro: Simplifies the main loop by removing a special case, which can eliminate branching and run faster.
Con: Increases code size by adding the separate “peeled” iterations.
5. Loop Unrolling
Reduces or eliminates loop overhead by performing the work of multiple loop iterations inside a single iteration.
Before
// This loop runs exactly 3 timesfor (int dx=-1; dx < 2; dx++) { result += filter[dx+1] * pixels[x+dx];}
After
// The loop is gone, replaced by its 3 iterations// dx = -1result += filter[0] * pixels[x-1];// dx = 0result += filter[1] * pixels[x+0];// dx = 1result += filter[2] * pixels[x+1];
Pro: Saves overhead cycles by removing the increment, compare, and jump instructions of the loop.
Con: Significantly increases code size. It’s only effective for loops where the iteration count is known and small.
6. Function Inlining
This is a function optimization that dramatically affects loops. It replaces a function call inside a loop with the actual code (the body) of that function.
Before
short sobel_mac(...) { // ... complex calculation ... return result;}for (int i=0; i < 1000; i++) { // This function is called 1000 times dest[i] = sobel_mac(source, i, ...);}
After
for (int i=0; i < 1000; i++) { // The code from sobel_mac is copied directly here short result = 0; // ... complex calculation ... dest[i] = result;}
Pro: Eliminates the high cost of a function call (passing parameters, jumping, and returning) for every iteration.
Con: Can cause a massive increase in code size, as the function’s body is duplicated every place it was called.
Other Loop Optimisations
Loop Reversal: Reverses the loop’s order (e.g., counting down to 0 instead of up). This can be faster on some hardware that has special “decrement-and-jump-if-not-zero” instructions.
Loop Skewing: A complex technique for nested loops that rearranges array accesses to improve data dependencies, often enabling other optimizations.
Compiler optimizations
How Compilers Optimize Code
A compiler’s job is broken into two main phases: Analysis (understanding the source code) and Synthesis (building the new machine code). Code optimization is a key part of the Synthesis phase.
The process generally follows these steps:
Intermediate Code Generation: The compiler first converts the source code into an intermediate, machine-independent format.
Code Optimization: It then optimizes this intermediate code. This is a machine-independent step. For example, it might optimize tmp1 := id3 * 60.0 and id1 := id2 + tmp1 from a more complex set of operations.
Code Generation: Finally, it generates the machine-dependent code (assembly) for the target platform. This stage may include further machine-dependent optimizations, like converting a multiplication by 2 into a single left-shift instruction.
Optimization Levels and Flags
Optimizations are typically controlled by the user via command-line flags.
Optimization Levels (-On): These are common flags that bundle groups of optimizations.
-O0: This level means no optimization.
-O1 / -O2: These levels apply optimizations targeting specific goals, such as execution speed or code size. The exact optimizations are specific to the compiler.
-O3: This is a highly aggressive optimization level that can sometimes even cause the code to function incorrectly.
Specific Flags: Compilers like GNU also offer flags for individual optimizations. Some are standalone, while others are included in the -O levels.
Loop Unrolling: Can be enabled with -funroll-loops or -funroll-all-loops. These are not necessarily included in the default optimization levels.
Function Inlining: The flag -finline-small-functions is an example of an inlining optimization that is included in the -O2 level.
Note: Optimization levels can have unintended side effects. For example, the -O2 level in the GNU compiler also enables -fdelete-null-pointer-checks, which may be undesirable.
Types of Compiler Optimizations
The documents highlight two main categories of optimization:
Local Optimizations: These are applied to small blocks of code. A compiler can perform these by:
Recognizing that an array is const during semantic analysis.
Replacing array accesses with the actual hard-coded numbers (e.g., -1, 0, 1).
Eliminating all multiplications by 0 and replacing multiplications by 1 during the intermediate optimization stage.
Global Optimizations: These are broader optimizations. An example is deciding how to pass function parameters. A compiler might choose to use registers instead of the stack, as this is often cheaper (faster).