Problem: Accessing main memory (RAM) is very slow (high latency).
Solution: Use a small amount of fast, on-chip memory to store frequently accessed data and code.
Principle of Locality: Programs tend to reuse data and code.
Temporal Locality: If an item is accessed, it’s likely to be accessed again soon (e.g., a variable in a loop).
Spatial Locality: If an item is accessed, items at nearby addresses are likely to be accessed soon (e.g., elements in an array).
2. Cache vs. Tightly Coupled Memory (TCM)
Feature
Cache
Tightly Coupled Memory (TCM)
Management
Hardware-managed
Software-managed (by the programmer)
Visibility
Transparent to the programmer.
Not transparent. Exists at a specific address in the memory map.
Access
Probabilistic: Fast on a hit, slow on a miss.
Deterministic: Always fast. No hits or misses.
Typical Use
General-purpose loop acceleration.
Critical, real-time code (ISRs), stacks, specific data (filter masks).
Blank
3. Cache Operations & Conflicts
Basic Operation
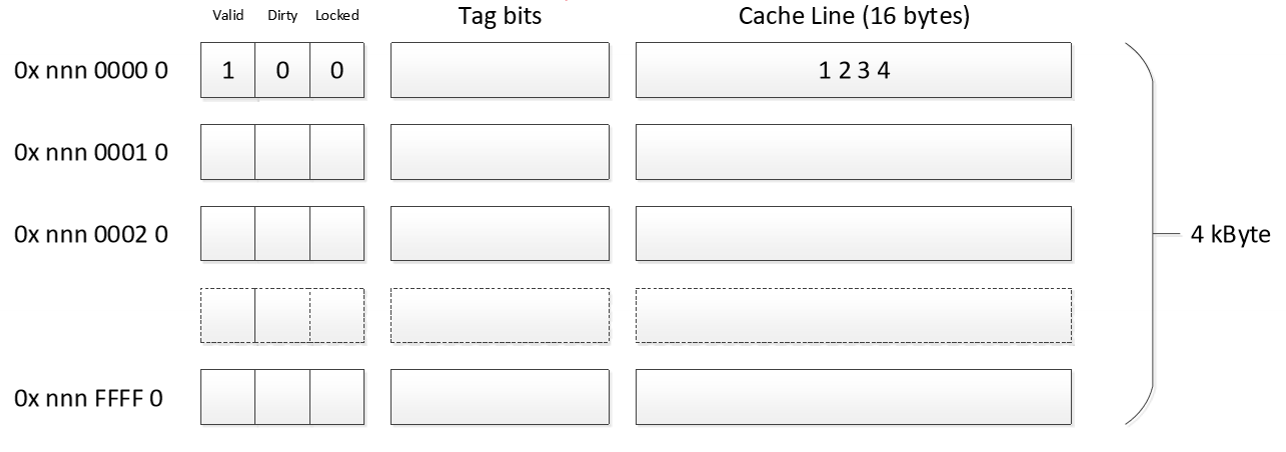
Cache Line: The smallest block of data that can be transferred between main memory and the cache.
Read Hit: CPU finds the data in the cache. This is fast.
Read Miss: CPU does not find data. CPU stalls, fetches the entire cache line from main memory, and then continues.
Write-Through Policy: Write data to both cache and main memory at the same time. Simple, but slower.
Copy-Back (Write-Back) Policy: Write data only to the cache and set a dirty bit. The data is only written back to main memory when the cache line is about to be replaced (evicted). This is faster.
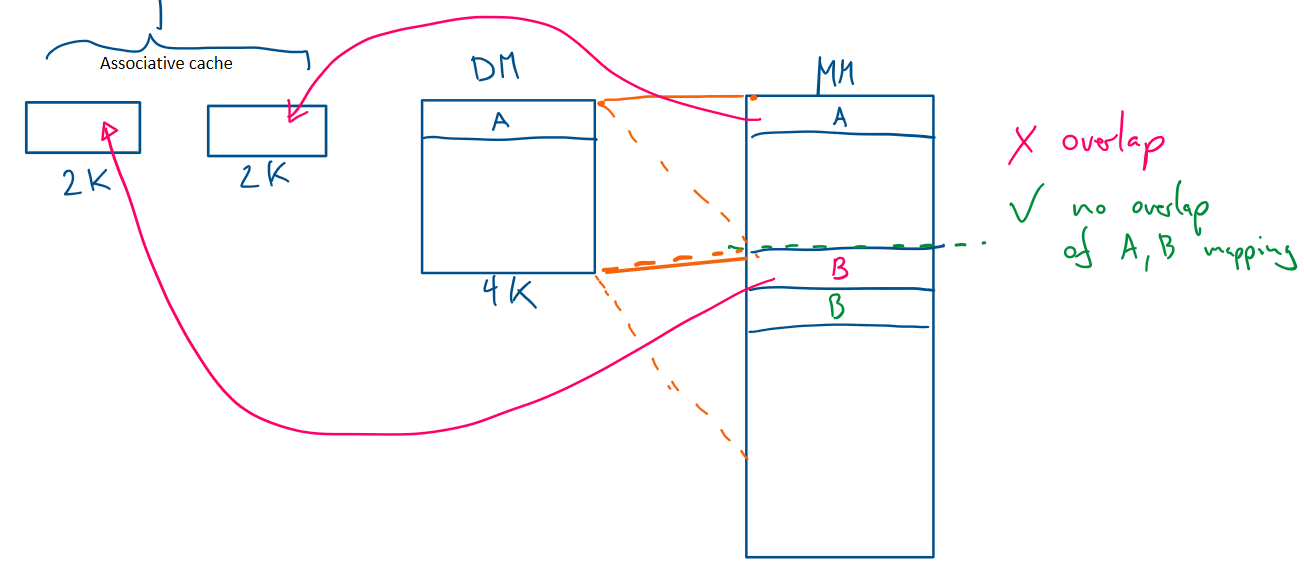
The Big Problem: Conflict Misses
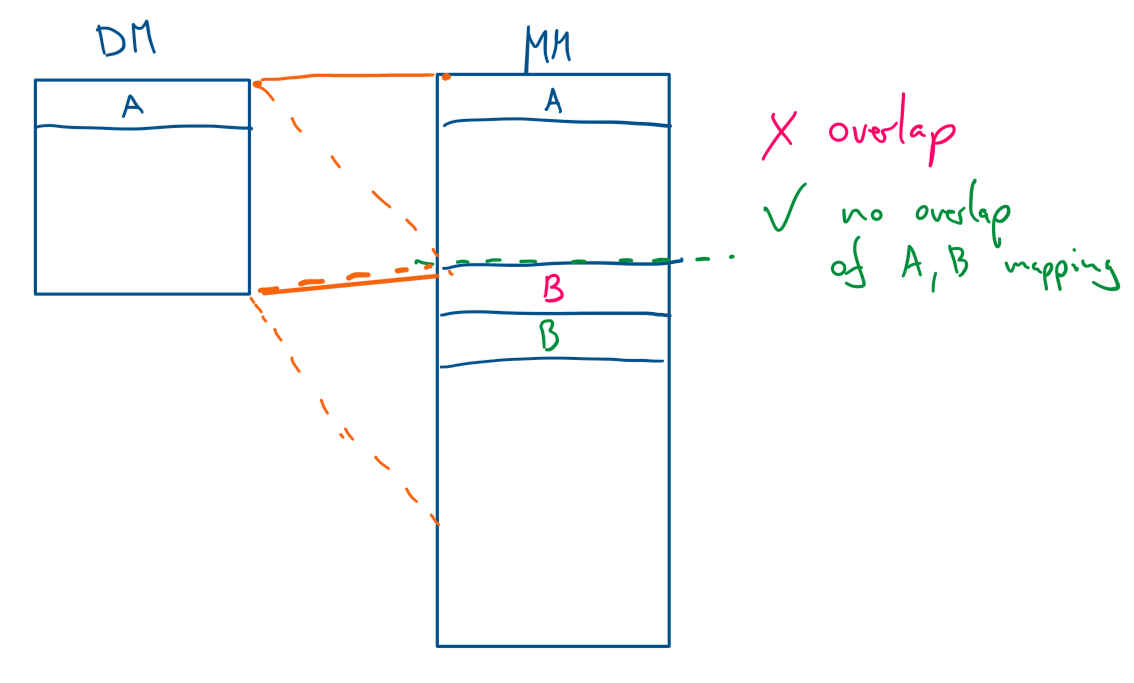
Direct-Mapped Cache: Each memory address can only be stored in one specific location (line) in the cache.
Memory alignment Conflict: If a loop accesses two arrays (e.g., a[i] and b[i]) and both a[i] and b[i] map to the same cache line, they will constantly evict each other. This is a conflict miss, and it makes the cache useless.
The Solution (Hardware):
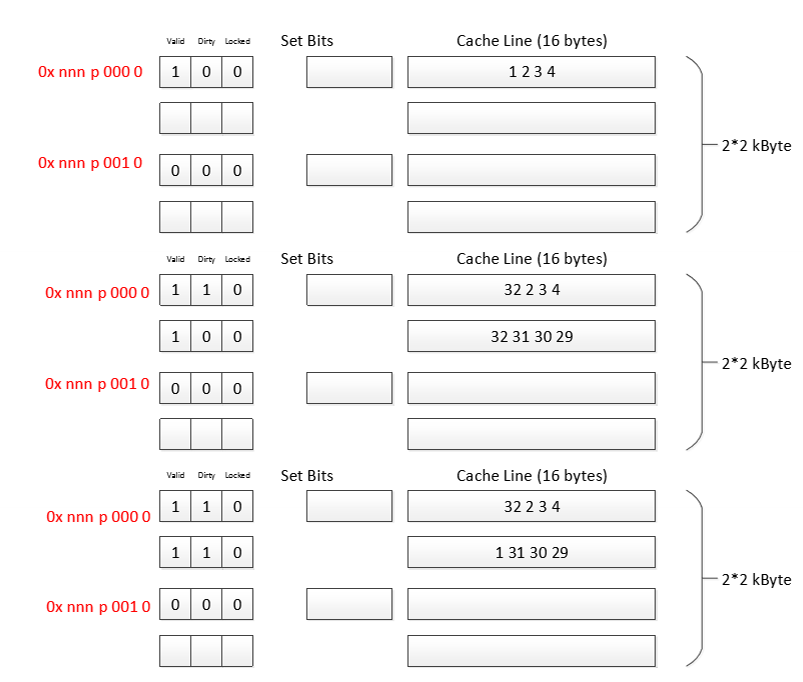
N-Way Associative Cache: Allows each cache set (index) to store N different lines. This greatly reduces conflict misses, as a[i] and b[i] can now coexist in the same set.
Multicolumn
Blank
Direct mapping
Multicolumn
Blank
Blank
Blank
N-Way Associative Cache
Multicolumn
Blank
Blank
Multicolumn
Blank
Addressing
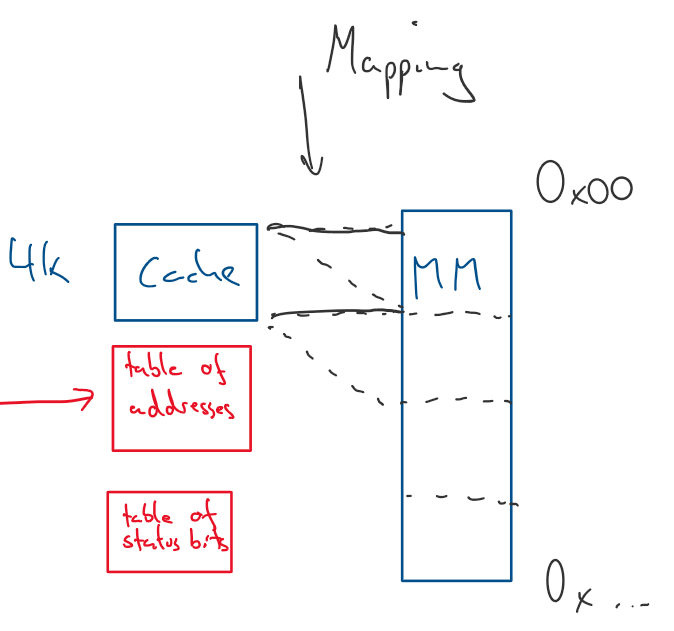
🗺️ How the Address is Mapped
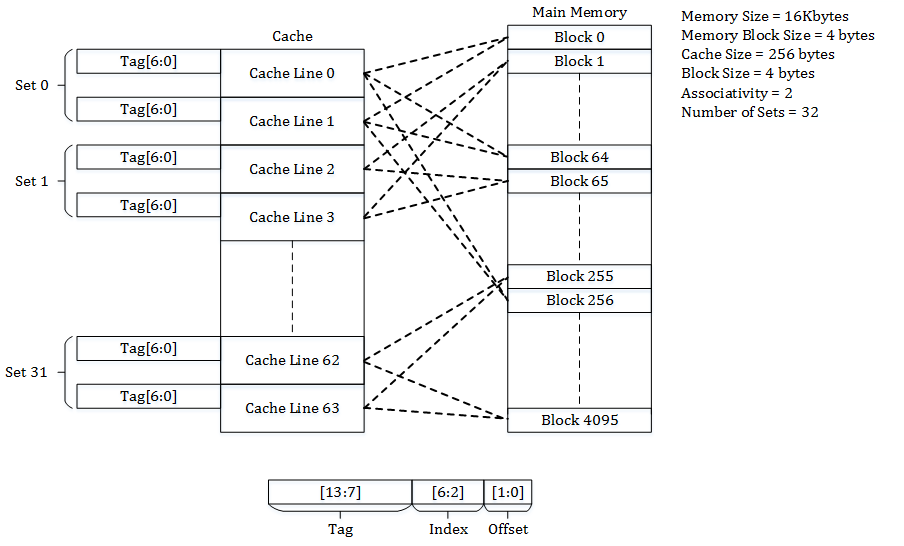
A memory address is broken into three parts to find data in the cache:
Tag
Set Index
Offset
Offset: This part identifies the specific byte inside a cache line.
Your diagram states each Cache Line is 16 bytes.
To select one of 16 bytes, you need 4 bits (24=16).
In your example addresses (e.g., 0x nnn p 000 0), the last hex digit 0 represents these 4 bits (00002), meaning the address is pointing to the start of that memory block.
Set Index: This part determines which set the memory block belongs to.
Your diagram shows two distinct sets: one for addresses like ...p 000... and another for ...p 001....
The bit that flips between 0 and 1 in that position is the Set Index. This means the cache shown has at least two sets (Set 0 and Set 1).
Tag: These are the remaining high-order bits of the address.
The tag is stored in the cache (in the box mislabeled “Set Bits”) to identify which of the many possible memory blocks (that all map to this same set) is currently stored in that line.
Blank
Multicolumn
Blank
4. Cache-Aware Programming Techniques
Techniques to manually improve cache performance.
1. Prefetching (non-blocking)
Goal: Hide memory latency by loading data into the cache before it is needed.
How: Use a special, non-blocking prefetch instruction (e.g., prefetch(&a[i+8])) inside your loop.
Key Idea: Fetch data for a future iteration while processing the current one.
Best Practice: Often combined with loop unrolling to fetch an entire cache line for the next block of unrolled instructions.
Can do HW pre-fetch : cache line fills on cache miss
2. Tiling (Loop Blocking)
Goal: Improve temporal locality (data reuse) when processing large data sets (like matrices or images) that don’t fit in the cache.
How: Code generally has sufficient locality to avoid cache misses. → Restructure nested loops to operate on small “tiles” or “blocks” of data that do fit in the cache.
Example (Matrix Transpose):
Bad (No Tiling): Iterates over the entire matrix. If the matrix is large, data is constantly evicted.
for (i=0; i<N; i++) for (j=0; j<N; j++) a[i][j] = b[j][i];
Good (Tiling): Uses four nested loops to process a BxB block at a time. The entire block stays in cache, maximizing reuse.
for (ii=0; ii<N; ii+=B) for (jj=0; jj<N; jj+=B) for (i=ii; i<ii+B; i++) for (j=jj; j<jj+B; j++) a[i][j] = b[j][i];
Related:
Loop Interchange: Swap inner/outer loops to ensure data is accessed sequentially (e.g., row-major order).
Loop Fusion: Combine two separate loops that iterate over the same data into one loop.
3. Cache Locking
Goal: Guarantee that critical code (e.g., an interrupt handler) or data is never evicted from the cache.
How: Load the item into the cache, then use a special instruction to “lock” that cache line or way.
Use Case: Provides predictable, low-latency response for critical functions.
Blank
5. Using Tightly Coupled Memory (TCM)
Placement: You must explicitly place data/code in TCM. This is done using linker scripts or compiler attributes (e.g., #pragma location=...).
What to Place in TCM:
Data: Stacks, frequently used arrays, filter coefficients.